大規模なマーケットプレイスやUGCサービスを運営する現場では、毎日膨大な投稿が流れます。その大半は健全な投稿ですが、ごく一部に風評や規約違反、なりすましといった「問題投稿」が混ざります。一見すると小さな比率に見えるこの「数%」をどう拾い切るかが、ブランドと利用者を守る要になります。
イー・ガーディアンでは、利用者数100万人を超える大規模サービスの投稿監視BPOにおいて、過去の人手チェックデータを用いてAI(ローカルLLMおよびBERT系分類モデル)を運用しています。本稿は、その仕組みを社内で設計・実装してきたAIエンジニアの視点から、「人が見るべき投稿だけをAIで絞り込む」現場設計と、ローカル学習を前提としたセキュアなファインチューニングの考え方をまとめたものです。
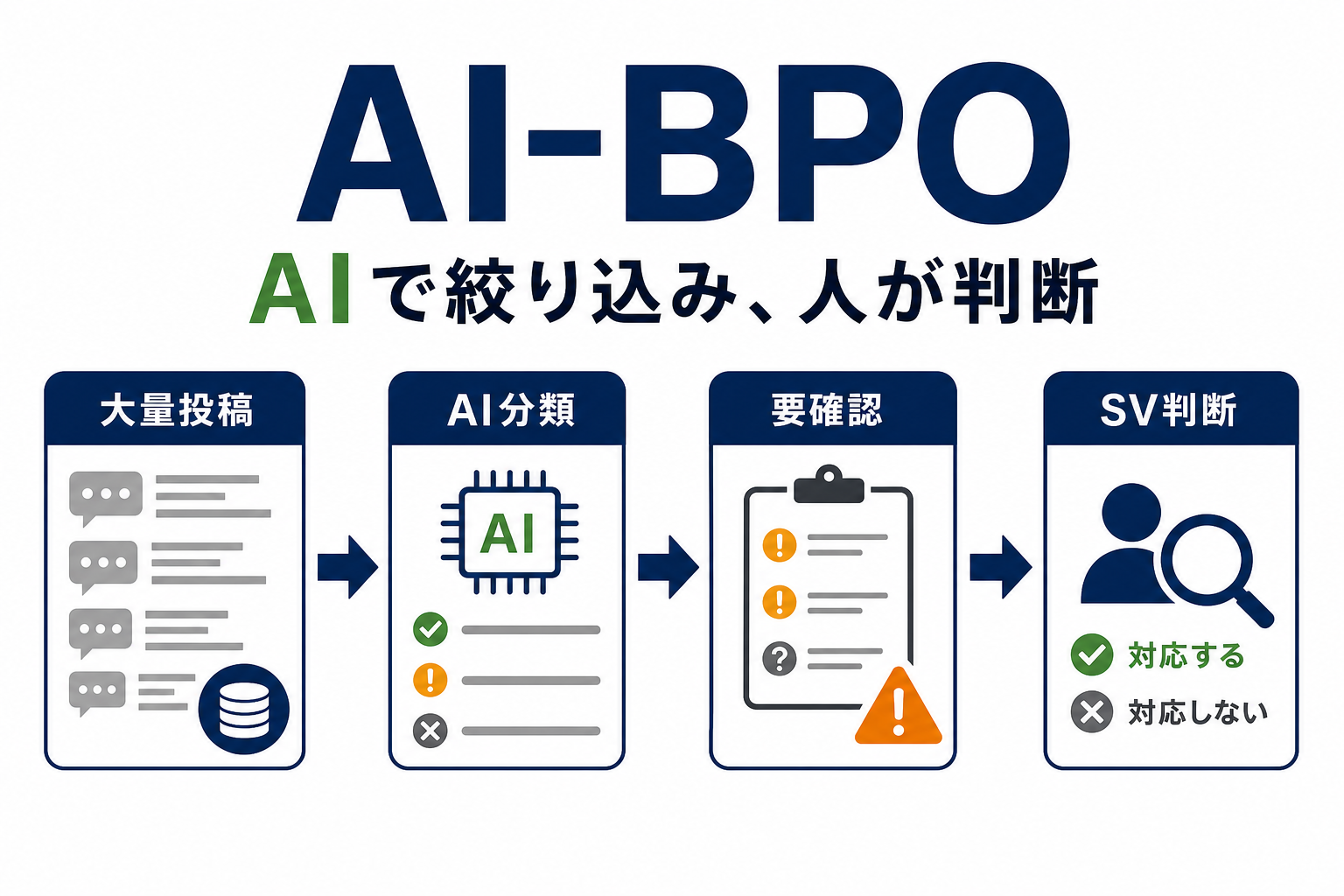
98%が正常、それでもオペレータが見続けなければならない理由
投稿監視BPOは、外から見ると「問題のある投稿を見つける仕事」に見えがちですが、現場では真逆の構造になっています。実際には、流入する投稿のおよそ98%は問題のない正常な内容で、注意すべき投稿は残り2%程度です。
たとえば、月間アクティブ200万人のサービスでユーザーが1日1回投稿すれば、月間で6,000万投稿に達します。2%でも120万件です。これだけの「問題候補」をすべて人手で掘り起こすには、必然的に98%の正常投稿にも目を通す必要があり、現場でチェックを担うオペレータと、オペレータを管理する管理者は、膨大な「異常でないもの」を読むことに時間を費やしてきました。
つまり、現場の本質的な負荷は「2%を見つけること」ではなく、「2%にたどり着くために、残り98%の正常データを延々と確認し続けること」にあります。エンジニアとして現場のオペレーションを観察したとき、ここが最も「AIで設計し直す価値のある工程」だと感じました。
教師データは「過去の投稿」と「人間の判定結果」だけでよい
AI化の第一歩は、新しいルールやガイドラインを書き起こすことではありません。すでに現場で積み上がっている「過去の投稿」と、それに対してオペレータおよび管理者が下してきた判定結果(問題あり/なしのラベル)を、そのまま教師データとして扱えるかたちに整えることです。
クライアント企業から事前に許諾を得たうえで、過去の人手チェック結果を学習データとして用い、現場ごとの判定傾向を再現できる分類モデルを構築します。ルール抽出やマニュアル化を経由せず、入力(投稿テキスト)と出力(判定ラベル)のペアだけで学習を回せる点が、BERT系の分類タスクとして扱う最大のメリットです。
ベースモデルは、生成AIではなく分類タスクに強いBERT系のEncoderモデルを採用しています。BERTはTransformerをベースとしつつも、テキスト生成ではなく入力文の意味理解と分類に特化したアーキテクチャで、投稿が「問題あり/なし」のどのクラスに属するかを判定するタスクとは相性が良いモデルです。生成AIで判定文を作らせるよりも、推論コスト・レイテンシ・再現性のすべてで運用に乗りやすい、というのが現場でモデルを選ぶ際の率直な感触です。
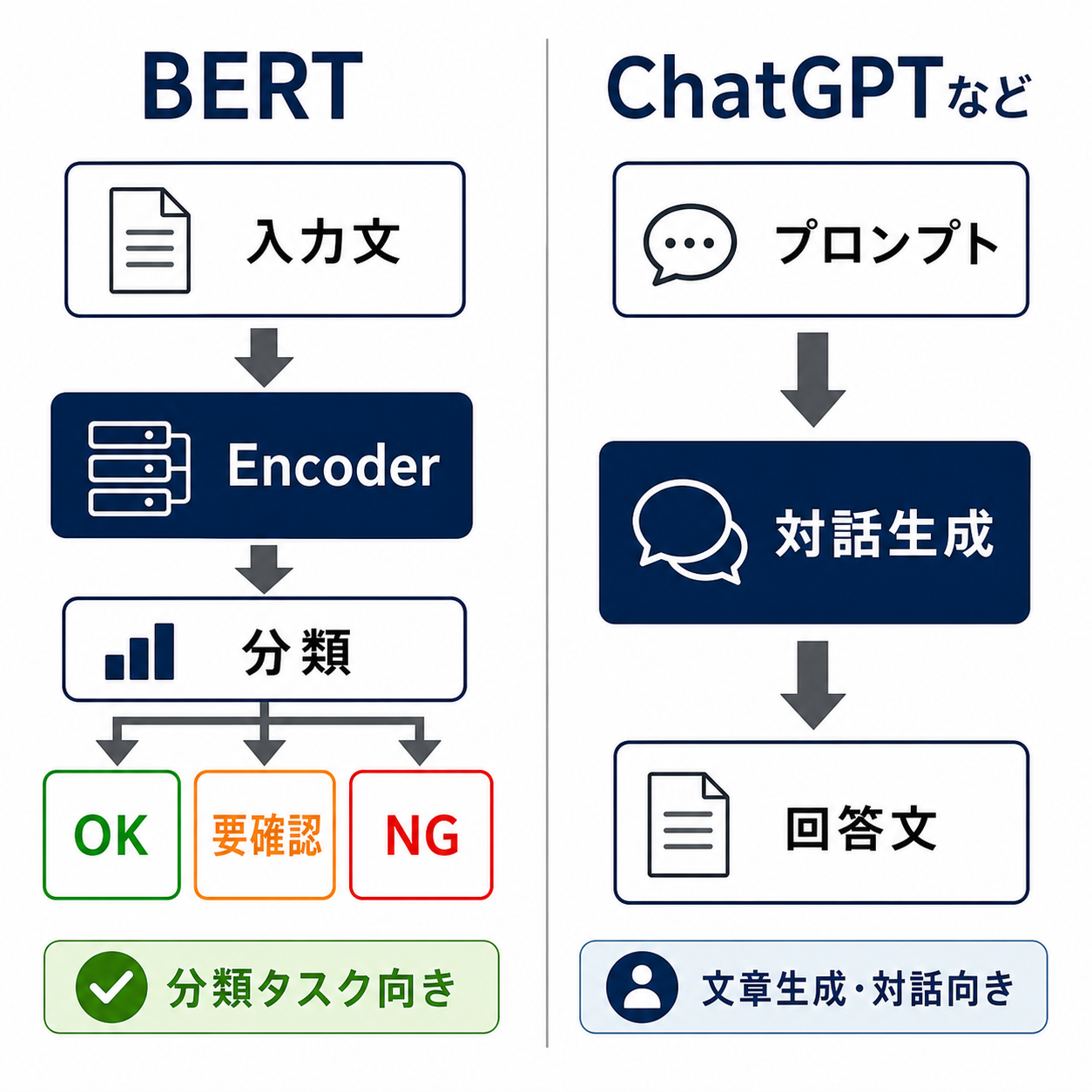
日本語の運用では、京都大学黒橋・褚・村脇研究室が公開している日本語DeBERTa V2(ku-nlp/deberta-v2-base-japanese)など、日本語コーパスで事前学習されたモデルをベースに採用しています。日本語特有の表記揺れや口語表現を一定程度吸収できることが、現場の精度を底上げします。
BPO業務そのものが「教師データを生み続ける装置」になっている
一般的なAI開発で最初にぶつかるのは、「教師データをどう用意するか」というハードルです。アノテーションを外注したり、社内で判定基準を作り直したり、初期投資のかなりの割合がここに消えていきます。
イー・ガーディアンの強みは、ここで時間と工程をスキップできる点にあります。投稿監視BPOという業務そのものが、長年にわたって「人間が判定済みの大量データ」を毎日積み上げてきているからです。クライアント企業ごとに数年単位の判定済みデータがすでに手元にあり、しかも実運用で揺れたグレーケースやエッジケースも含まれています。これは机上で作った教師データとは性質が違う、現場で鍛えられた学習データです。
運用が続く限り、新しい投稿と新しい判定結果が日々追加され、モデルを更新し続けられる構造になっています。「業務 → 判定済みデータ → AI更新 → 業務効率化 → さらに精度の高い判定データ」というループが自然に回るのが、BPO事業者がAIを内製する場合の最大のアドバンテージです。
この仕組みは投稿監視に限らず、人手判定が日常的に発生する他のBPO領域 — カスタマーサポートの問い合わせ分類、コンテンツ審査、不正検知、画像レビューなど — にも同じ構造で転用できます。「業務でデータが溜まる」「人間の判定がラベルになる」「ローカルで学習しクラウドで推論する」という3点がそろう領域であれば、本稿の設計思想はそのまま適用可能です。
クラウドとローカルの役割分担:ファインチューニングはオンプレ、推論はGCP/AWS
投稿監視BPOで扱うデータは、その多くがクライアント企業の非公開情報です。ユーザー投稿には個人情報や未公開のキャンペーン情報、内部の運用上のやり取りが混ざることもあり、外部サービスに学習データを安易に流すことはできません。そのためイー・ガーディアンでは、「学習はローカル、推論はクラウド」という役割分担を基本方針にしています。
ローカル学習側では、NVIDIAのパーソナルAIワークステーション「DGX Spark」を自社に導入し、完全オフライン環境でファインチューニングを行える体制を整備しています。DGX SparkはGB10 Grace Blackwell Superchipと128GBの統合メモリを備えるデスクトップ型のAIワークステーションで、ローカル環境のままBERT系の分類モデルから比較的大きなLLMまでチューニングできるのが特長です。(参考:NVIDIA DGX Spark)
このローカル環境で学習したモデルを、案件の要件に応じてGCPのVertex AI、またはAWSのAmazon Bedrock側にデプロイし、API経由で監視業務から呼び出せるようにします。クラウド選定は、クライアント企業の既存インフラやセキュリティ要件に合わせて使い分ける方針です。学習プロセスがクラウドに学習データを送らないため、原理的に「未公開データが外に出ない」状態を維持しながら、推論側はクラウドの可用性とスケーラビリティを使えるという構成になります。
監視UIへの組み込み:Chrome拡張で「現場の見え方」を変える
BPOという業務特性上、監視オペレータが日々向き合うのは、多くの場合クライアント企業から提供される管理画面です。新たに監視専用のシステムを立ち上げるのではなく、既存の管理画面を活かしたまま、その上にAIの判定を被せるのが現場では最も実装しやすいアプローチになります。
具体的には、クラウド側にデプロイされた分類モデルのAPIを、Google Chromeの拡張機能経由で監視画面に呼び出し、各投稿のスコアやリスクラベルをオペレータの作業画面上に表示します。これにより、オペレータは「全件をまず読む」のではなく、「AIが要注意とした投稿から確認する」フローへ自然に切り替わります。
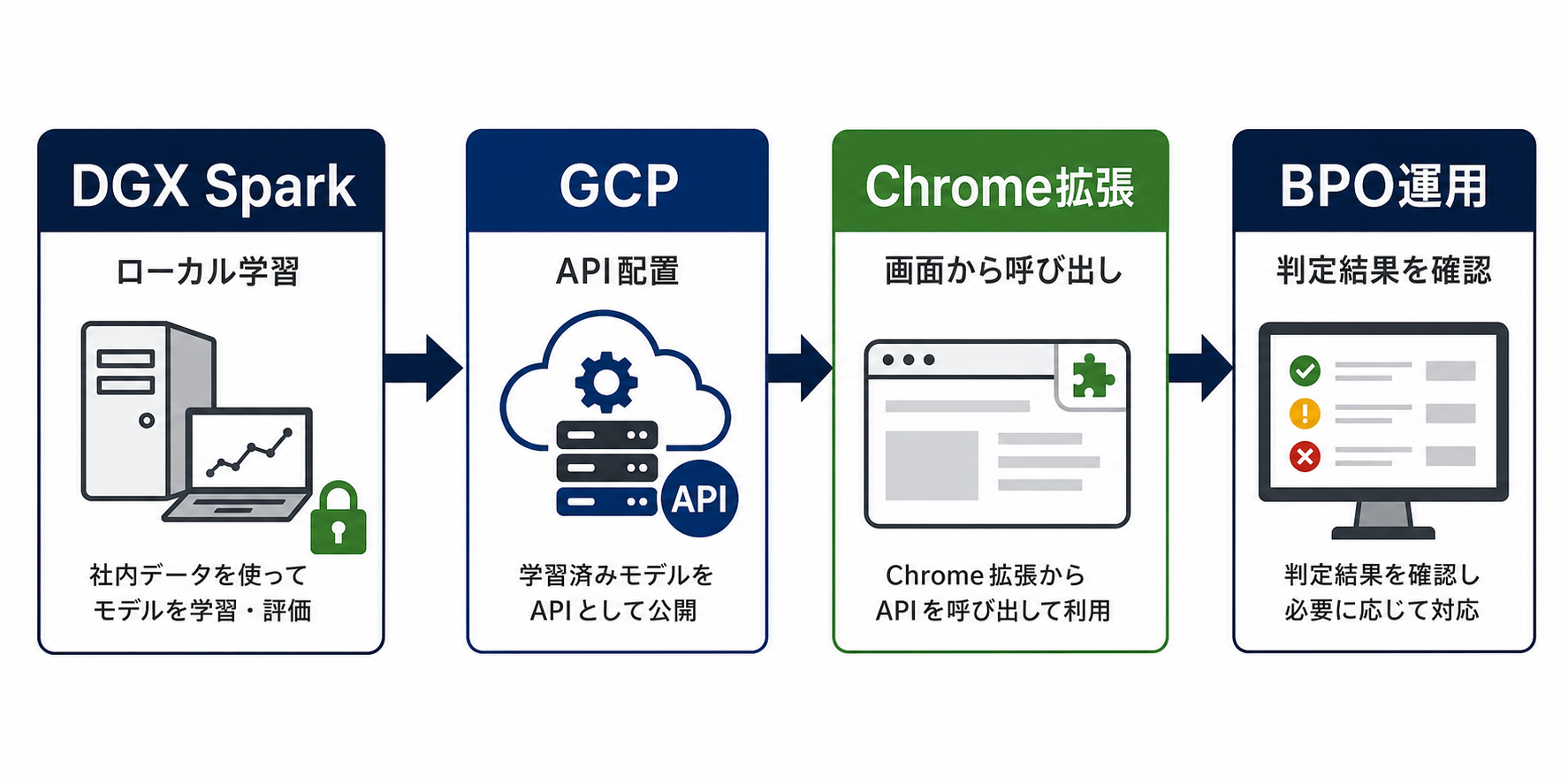
裏側では、案件要件によってバックエンドのモデルや配置先(Vertex AI / Bedrock)を切り替えられるよう、APIインターフェースを共通化しています。クライアントごとに最適なクラウドを選びながら、現場のオペレーション手順は変えずに済む点が、BPO提供側にとっては運用の鍵になります。
効果:オペレータは「判断」に集中し、管理者は「品質管理」に時間を使えるようになる
AI化によって最も変わったのは、オペレータと管理者の時間の使い方です。従来は「2%を発見するために98%を読む」必要がありましたが、AIが事前に大半の正常投稿をふるい落とすことで、オペレータが目を通すべき母数を大きく圧縮できるようになりました。
この変化は、単なる工数削減にとどまりません。AIエンジニアの観点から運用全体を見ると、オペレータと管理者の役割は次の3つに再配分されます。
- オペレータによるグレーゾーンの判定:AIが要注意とした投稿に対して、サービスの文脈を踏まえた一次判定を行います。
- 管理者による品質管理とエスカレーション対応:オペレータの判定結果のサンプリングレビュー、難判定ケースの最終判断、クライアントへのエスカレーションに時間を使えるようになります。
- 教師データの更新とAIの誤判定監視:新しい手口や規約改定に合わせて学習データを更新し、AIの誤判定・取りこぼしを継続的にモニタリングします。
AIに任せられるのは「あきらかに正常」と「あきらかに問題」のスクリーニング、人が残すのは「どちらとも言えない投稿」と「事業リスクの判断」。この役割分担を明示的に設計することで、98%を機械に任せながら、最も重要な2%の判断品質を逆に高めることが可能になります。
ニッチな運用課題こそ、AIエンジニアと現場が一緒に設計する対象になる
投稿監視BPOは、外からは見えにくい業務です。しかし、その内側には「大量の正常データを延々と確認する」「サービス固有の判断ルールが言語化しきれていない」「未公開データを外部に出せない」といった、ニッチで切実な課題が積み重なっています。
こうした課題は、汎用的な生成AIをそのまま当てるだけでは解けません。必要なのは、過去の投稿と判定結果という現場にすでにあるデータを起点に、「どこをAIに任せ、どこを人に残すか」を一件ごとに設計すること、そして「学習はローカル、推論はクラウド」のように、セキュリティと運用性を両立させる構成を選ぶことです。
イー・ガーディアンは現在、第2創業期と位置付け、新規のご提案は原則としてAI活用を前提に設計しています。日本国内および海外の運用拠点で日々蓄積される判定済みデータを起点に、AIエンジニアと現場の管理者・オペレータが同じテーブルで設計を進めることで、人とAIの役割分担を案件ごとに組み立てていく。投稿監視に限らず、CS、コンテンツ審査、不正検知といった他のBPO領域にも同じ思想で展開しており、「業務でデータが溜まり、AIがそのデータで賢くなり、現場をさらに楽にする」サイクルを案件ごとに作っていきます。投稿監視のような一見ニッチな現場ほど、AIを「導入する」のではなく「設計する」発想が、これからの運用品質を分けていきます。
■ 投稿監視サービスの詳細はこちら
■ イー・ガーディアンのAIに関する取り組みの詳細はこちら
サービスに関するお問い合わせ・お見積もりはこちらから

